
s3 버킷을 만들었으니 우선 python에서 s3에 접근해보겠습니다
s3 버킷 생성 방법은 아래의 글을 참고해주세요
2022.09.03 - [aws/s3] - [ aws S3 ] S3 (Simple Storage Service) bucket 만들기
[ aws S3 ] S3 (Simple Storage Service) bucket 만들기
aws s3를 이용해보려고 합니다 s3를 이용할 때는 버킷을 먼저 만들어줘야 합니다 버킷을 만들어 보겠습니다 우선 일반 구성부터 설정해줍니다 버킷 이름 : testbucket + 본인 이름(영어)으로 해줄게요
kwon-eb.tistory.com
필요한 모듈
우선 python에서 aws를 이용하는 데 필요한 설치부터 하겠습니다
pip install boto3
s3 접속
이제 vscode를 하나 열어서 python 파일을 하나 만들어 줍니다
저는 s3.py라고 만들었습니다
# s3.py
import boto3
import os
AWS_ACCESS_KEY_ID = os.environ['AWS_ACCESS_KEY_ID']
AWS_SECRET_ACCESS_KEY = os.environ['AWS_SECRET_ACCESS_KEY']
def connection_s3():
"""
connection aws s3 user
Returns:
s3_client: aws s3 user
"""
try:
print("connection_s3 start")
s3_client = boto3.client(service_name="s3",
aws_access_key_id=AWS_ACCESS_KEY_ID,
aws_secret_access_key=AWS_SECRET_ACCESS_KEY)
return s3_client
except Exception as e:
print(e)
raise
finally:
print("connection_s3 end")
if __name__ == "__main__":
try:
s3_client = connection_s3()
print(s3_client)
except Exception as e:
print(e)
finally:
print("bucket finish")
잠시 코드 설명을 하겠습니다
저는 aws의 키 페어를 가지고 s3에 접근했는데요
AWS_ACCESS_KEY_ID = access key
AWS_SECRET_ACCESS_KEY = secret key
입니다
파일을 실행했을 때 결과가
이런 식으로 나오면 성공입니다
파일 업로드
이제 파일을 한번 올려보겠습니다
txt, csv 두 가지 종류로 한번 해보려고 합니다
우선 s3.py랑 같은 폴더 안에 a.text, b.csv를 넣어줍니다
# s3.py
import boto3
import os
AWS_ACCESS_KEY_ID = os.environ['AWS_ACCESS_KEY_ID']
AWS_SECRET_ACCESS_KEY = os.environ['AWS_SECRET_ACCESS_KEY']
AWS_BUCKET_NAME = os.environ['AWS_BUCKET_NAME']
file_name_list = ["a.text", "b.csv"]
def connection_s3():
"""
connection aws s3 user
Returns:
s3_client: aws s3 user
"""
try:
print("connection_s3 start")
s3_client = boto3.client(service_name="s3",
aws_access_key_id=AWS_ACCESS_KEY_ID,
aws_secret_access_key=AWS_SECRET_ACCESS_KEY)
return s3_client
except Exception as e:
print(e)
raise
finally:
print("connection_s3 end")
def upload_file_def(s3_client):
"""
s3 upload file -- txt, csv etc
Args:
s3_client (aws user): aws s3 user
"""
try:
for file_name in file_name_list:
# 올릴 파일이름, 버킷 이름, 버킷에 저장될 파일 이름
s3_client.upload_file(f"./{file_name}", AWS_BUCKET_NAME, f"{file_name}")
print(f"{file_name} upload success")
except Exception as e:
print(e)
finally:
print("upload_file_def end")
if __name__ == "__main__":
try:
s3_client = connection_s3()
upload_file_def(s3_client)
except Exception as e:
print(e)
finally:
print("bucket finish")
기존에 있던 s3.py 파일에
upload_file_def라는 함수를 추가했습니다
이 함수는 a.text, b.csv를 업로드하는 역할을 합니다
for 문법은 다들 아시리라 생각하고 넘어가겠습니다
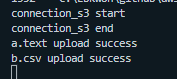
로직을 실행했을때 이렇게 나오면 aws s3에 내 버킷 안으로 들어가서 확인해봅시다
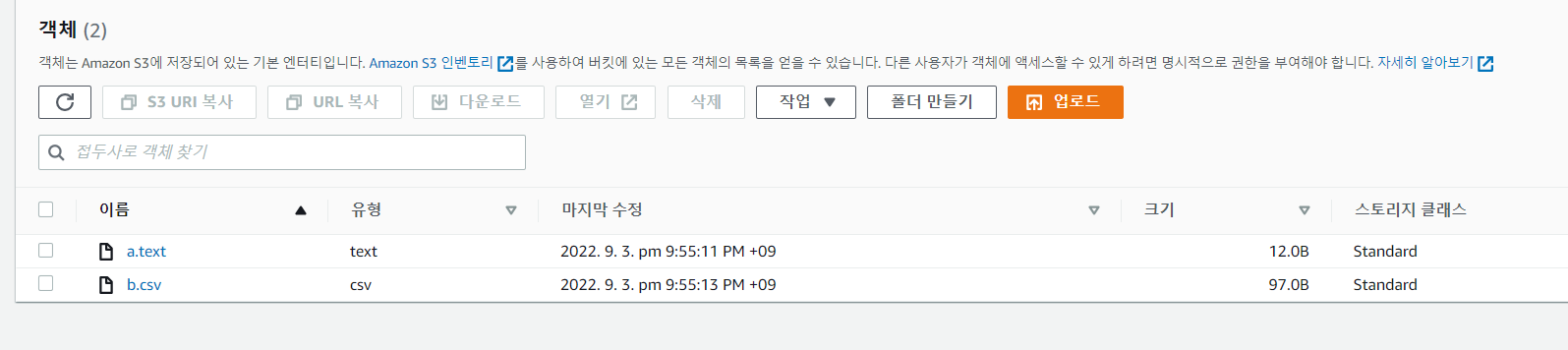
파일 두 개가 추가된 것을 확인할 수 있습니다
파일을 읽는 방법이나 삭제하는 방법은 다음 글에 이어서 쓰겠습니다
'programing > aws' 카테고리의 다른 글
| [ aws RDS ] postgresql 데이터베이스 생성 및 연결, 삭제해보기 (0) | 2023.01.12 |
|---|---|
| [ aws IAM ] 유저 그룹, 유저 생성 (0) | 2023.01.12 |
| [ aws ecr ] ecr 만들기 (0) | 2022.09.17 |
| [ aws s3 ] python으로 bucket에서 파일 읽기, 삭제하기 (0) | 2022.09.03 |
| [ aws S3 ] S3 (Simple Storage Service) bucket 만들기 (0) | 2022.09.03 |




댓글